|
|
CLEF Question Answering Track
Question Answering, Natural Language, Linked Data, Semantic Indexing, Logical Inference, Textual Inference |
General ScenarioIn the current general scenario for the CLEF QA Track, the starting point is always a Natural Language question. However, answering some questions may need to query Linked Data (especially if aggregations or logical inferences are required), whereas some questions may need textual inferences and querying free-text, and finally, answering some queries may need both. 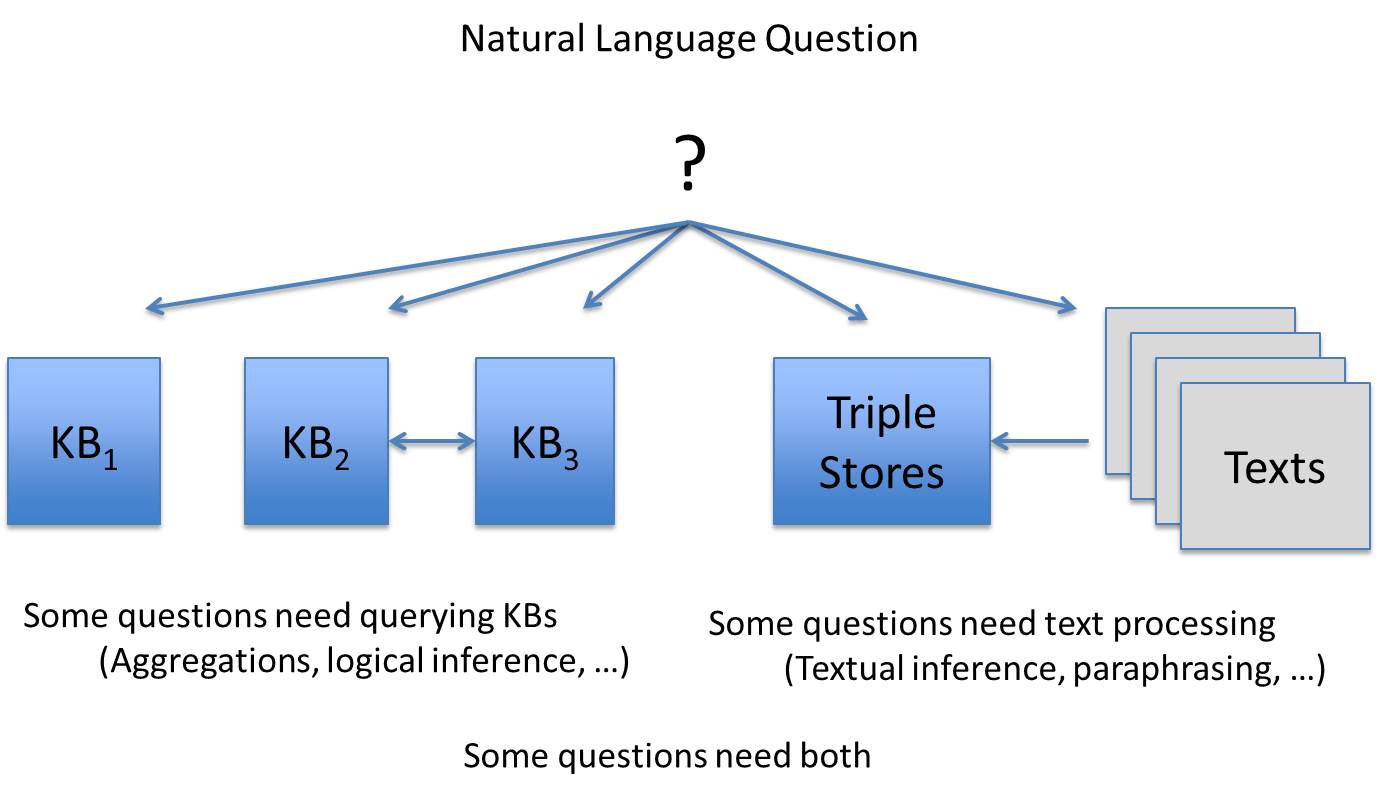
As a matter of example related to CLEF eHealth, consider the use case where patients receive medical reports they don't understand. Given this report, patients have lots of questions. Some of them will need general definitions as one can find in wikipedia. Some might need more complex answers about the relations between symptoms, treatments, etc. We want to help them understand. So, given this general scenario, CLEF QA Track will work on two instances: one targeted to (bio)medical experts (BioASQ Tasks) and a second targeted to Open Domains (QALD and Entrance Exams Tasks). In the first one, medical KBs, ontologies and articles must be taken into account. In the second one, general resources such as Wikipedia articles and DBpedia will be considered. TasksQALD: Question Answering over Linked DataQALD-4 is the fourth in a series of evaluation campaigns on multilingual question answering over linked data, this time with a strong emphasis on interlinked datasets and hybrid approaches using information from both structured and unstructured data. The exercises are: Multilingual Question Answering (answers from an RDF data repository given a natural language question), Question Answering on Interlinked Data (questions require information from at least two interlinked biomedical datasets), and Hybrid Question Answering (questions over DBpedia that require a combination of structured information and raw text available in the DBpedia abstracts). More info at: http://www.sc.cit-ec.uni-bielefeld.de/qaldBioASQ: Biomedical semantic indexing and question answeringThe challenge (aka competition or shared task) will assess:
Entrance ExamsJapanese University Entrance Exams include questions formulated at various levels of complexity and test a wide range of capabilities. The challenge of "Entrance Exams" aims at evaluating systems under the same conditions humans are evaluated to enter the University. In this first campaign we will reduce the challenge to Reading Comprehension exercises contained in the English exams. More types of exercises will be included in subsequent campaigns (2014-2016) in coordination with the "Entrance Exams" task at NTCIR. Exams are created by the Japanese National Center for University Admissions Tests. The "Entrance Exams" corpus is provided by NII's Todai Robot Project and NTCIR RITE. More info at: http://nlp.uned.es/entrance-examsImportant Dates
Organizing CommitteeElena Cabrio (INRIA Sophia-Antipolis Mediterranee, Cedex, France) Anastasia Krithara (NCSR "Demokritos", Greece) Eduard Hovy (Carnegie Mellon University, USA) Axel Ngonga (University Leipzig, Germany) George Paliouras (NCSR "Demokritos", Greece) Anselmo Peñas (UNED, Spain) Alvaro Rodrigo (UNED, Spain) Richard Sutcliffe (University of Essex, UK) Christina Unger (CITEC, Universitat Bielefeld, Germany) ContactAnselmo Peñas (anselmo@lsi.uned.es) Suported by: |