Resources
Creating resources enriched with annotator meta-data:
sensor and demographic data
Solutions
Designing Human-Centric AI (HCAI) systems
Evaluation
New methodologies and evaluation metrics focused on human-centric principles
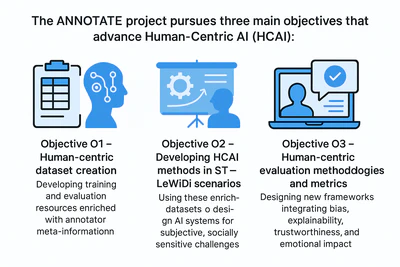
Human-Centric AI, end-to-end
The ANNOTATE project advances Human-Centric AI (HCAI)—systems that prioritise human needs, values, and capabilities, assisting rather than replacing people. Our approach embeds human input across the full AI pipeline
- Human-enriched resources: Training and evaluation datasets that keep all annotators’ labels and annotator meta-information (sensor data such as eye-tracking, heart rate, EEG; demographic/social attributes; and process feedback).
- HCAI systems: Models that leverage this meta-information to deliver explainable, inclusive, and context-sensitive outputs with high response quality.
- Human-centric evaluation: Techniques and metrics that go beyond accuracy, covering bias detection, explainability, informativeness, trustworthiness, and potential emotional impact.
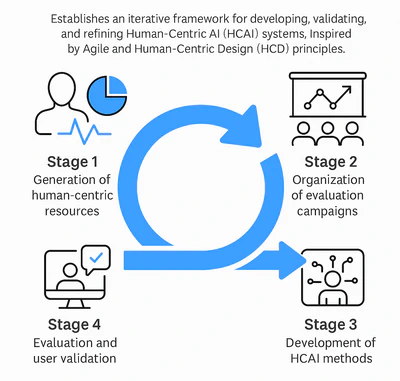
ANNOTATE Methodology Cycle
The ANNOTATE Methodology Cycle establishes an iterative framework for developing, validating, and refining Human-Centric AI (HCAI) systems. Inspired by Agile and Human-Centric Design (HCD) principles, it ensures continuous improvement, ethical alignment, and usability in real-world contexts.
- Stage 1 – Generation of human-centric resources: Creation of datasets enriched with demographic, sensor-based, and feedback data from annotators. These resources serve as the foundation for developing and evaluating fair, inclusive, and transparent AI systems.
- Stage 2 – Organization of evaluation campaigns: Conducting national and international benchmarking events using the generated resources. These campaigns validate models, encourage collaboration, and promote reproducibility within the research community.
- Stage 3 – Development of HCAI methods: Designing AI systems that integrate human feedback, sensor data, and disagreement-aware learning, addressing socially sensitive challenges while remaining adaptive and ethical.
- Stage 4 – Evaluation and user validation: Implementing human-in-the-loop evaluations to test performance, fairness, and emotional impact. Feedback from users and partners drives continuous refinement across all stages.
Research & Innovation
Metadata from annotators
We integrate sensor data (eye-tracking, heart rate, EEG), demographic information, and annotator feedback to better understand how people perceive and label each case.
Strong Learning with Disagreement (ST-LeWiDi)
Instead of collapsing annotations into a single label, we preserve all annotators’ inputs and meta-information, using disagreement as a valuable signal for model training and evaluation.
Human-Centric AI Systems
We design AI models that prioritize human needs and values, focusing on explainability, inclusiveness, response quality, and contextual sensitivity.
Multi-Criteria Human-Centric Evaluation
Evaluation goes beyond accuracy — including bias detection, explainability, informativeness, trustworthiness, and even the emotional impact of AI outputs on users.
Ethics, Privacy & Data Governance
The approach is tested on diverse scenarios - (i) sexism detection on social media, (ii) disinformation during crises, (iii) multimodal mental health analysis, and (iv) real-time transcription for accessibility.
Cross-Domain Validation through Four Use Cases
The approach is tested on diverse scenarios - (i) sexism detection on social media, (ii) disinformation during crises, (iii) multimodal mental health analysis, and (iv) real-time transcription for accessibility.
Partners
UNED – NLP & IR Group
UNED leads the project’s work on evaluation metrics and methodologies for Human-Centric AI (HCAI). With extensive experience in dataset creation and model validation, the team ensures progress toward Objective O3 (human-centered evaluation). UNED has pioneered resources that capture annotator disagreement in Spanish and English—such as the EXIST 2023, 2024 and 2025 datasets—and co-organizes the EXIST challenge with UPV, engaging researchers worldwide in sexism detection and categorization.
UB – CLiC Research Group
UB’s CLiC group leads the creation of multilingual annotated linguistic resources, providing key datasets for Objective O1. Their expertise in machine learning for language and speech analysis supports the development of multimodal resources with disagreement, used to train models for sexism detection and impaired speech recognition. CLiC also contributes its strong background in organizing shared tasks such as DETOXIS, DETESTS, and DETESTS-Dis, in collaboration with UPV and UNED.
UPV – PRHLT Research Center
UPV brings extensive expertise in natural language processing (NLP) and multimodal analysis for detecting disinformation, hate speech, and mental health disorders on social media. Their strength in combining text and physiological data—including eye-tracking, EEG, and heart rate—is central to Objective O2. With experience in creating datasets and organizing over 50 international evaluation campaigns (IberEval, CLEF, FIRE, EvalIta, SemEval).
This work was supported by the Spanish Ministry of Science, Innovation and Universities (project ANNOTATE (PID2024-156022OB-C31, PID2024-156022OB-C32 and PID2024-156022OB-C33)) funded by MICIU/AEI/10.13039/501100011033 and the European Social Fund Plus (ESF+).



"Interested in Human-Centric AI or our research outcomes? Get in touch with the project coordinator — we’d love to hear from you!"
Laura Plaza – lplaza@lsi.uned.es
Jorge Carrillo-de-Albornoz – jcalbornoz@lsi.uned.es
Paolo Rosso – prosso@dsic.upv.es
Carlos David Martínez – cdmartinez@prhlt.upv.es