Multilingual Web Person Name Disambiguation (M-WePNaD)
Introduction
M-WePNaD is a shared task on the disambiguation of person names on the Web, which takes into account its multilingual nature.
Nowadays, many of the queries entered into web search engines are composed of person names. For a search of this kind including a person name, one may want to be able to know the number of different individuals included in the search results as well as to see a breakdown of results clustered for each specific individual. This is a task that has attracted substantial interest in the scientific community in recent years, evident in a number of share tasks that have tackled it (WePS-1, WePS-2, WePS-3). Despite the Web’s multilingual nature, existing work on person name disambiguation has not considered search results in multiple languages. The objective of this task will be centered around the person name disambiguation task from web search results, with the additional challenge that results for a query, as well as each individual, can be written in multiple languages.
The organizing committee will provide the participants with the training corpus to be used for the development of their systems. A test corpus will be provided later to evaluate the performance of the systems they developed.
Final results of this task will be presented and discussed as part of the IberEval 2017 workshop, which will take place in Murcia, Spain, on the 19th September, 2017, co-located with SEPLN 2017.
Description
The person name disambiguation task on the Web consists in distinguishing the different individuals that are contained within the search results for a person name search query. It can be defined as a clustering task, where the input is a ranked list of n search results, and the output needs to provide both the number of different individuals identified within those results, as well as the set of pages associated with each of the individuals. While the task has been limited to monolingual scenarios so far, this task will be assessed in a multilingual setting.
We have compiled an evaluation corpus called MC4WePS, which has been manually annotated by three experts. This corpus will be used to evaluate the performance of multilingual disambiguation systems. The evaluation can be carried out for different genres as the corpus includes not only web pages but also social media posts.
The MC4WePS has been split into two parts, one for training and one for testing. Participants will have nearly two months to develop their systems making use of the training corpus (see Important Dates). Afterwards, the test corpus will be released, whereupon participants will run their systems to then send the results back to the task organizers. The organizers will evaluate the performance of the participants and put together a ranked list of systems.
More details about the corpus can be found on the Resources section. It is worth noting that different person names in the corpus have different degrees of ambiguity, a web page can be multilingual, and not all the contents in the corpus are HTML pages, but also other kinds of contents are included, including social media posts. To facilitate access to different types of documents, all the contents have been processed with Apache Tika (https://tika.apache.org/), and the resulting texts have also been included in the corpus.
We also provide the performance scores for different baseline approaches. Participants will be restricted to the submission of five different result sets. They will then write a paper (working note) describing their systems. Further guidelines describing the format of the result files and the paper can be found in the Submission section.
Important dates
13 Mar, 2017: Training set released.
12 May, 2017: Test set released.
16 May, 2017: Deadline for submission of results. Extended deadline: 18 May, 2017.
22 May, 2017: Competition results announced: 23 May, 2017.
05 Jun, 2017: Deadline for participants to submit Working notes. Extended Deadline: 15 Jun, 2017
15 Jun, 2017: Reviews of Working notes sent out to authors. Extended Deadline: 22 Jun, 2017
01 Jul, 2017: Deadline to submit revised Working notes.
19 Sep, 2017: Workshop at SEPLN 2017.
Resources
The corpus was collected in 2014, issuing numerous search queries and storing those that met the requirements of ambiguity and multilingualism.
Each query included a first name and last name, with no quotes, and searches were issued in both Google and Yahoo. The criteria to choose the queries were as follows:
Ambiguity: non-ambiguous, ambiguous or highly ambiguous names. A person’s name is considered highly ambiguous where it has results for more than 10 individuals within the first 100 to 300 results. Cases with 2 to 9 individuals were considered ambiguous, while those with a single individual are deemed non-ambiguous.
Language: results can be monolingual, where all pages are written in the same language, or multilingual, where pages are written in more than one language. Moreover, results can be monolingual or multilingual when it comes to the documents pertaining to a certain individual.
More details related with the corpus can be found here.
Training Corpus
M-WeP-NaD Training Corpus
The M-WeP-NaD training corpus includes 65 different person names belonging to the MC4WePS benchmark corpus [Montalvo et al., 2016], which have been randomly sampled.
The corpus comprises the following person names:
|
PersonName |
#Webs |
#C |
%S |
%NRs |
L |
%OL |
|
Adam Rosales |
110 |
8 |
9.09% |
10.0% |
EN |
0.91% |
|
Albert Claude |
106 |
9 |
10.38% |
24.53% |
EN |
13.21% |
|
Álex Rovira |
95 |
20 |
23.16% |
6.32% |
EN |
43.16% |
|
Alfred Nowak |
109 |
15 |
3.67% |
66.06% |
EN |
30.28% |
|
Almudena Sierra |
100 |
22 |
12.0% |
63.0% |
ES |
1.0% |
|
AmberRodríguez |
106 |
73 |
11.32% |
10.38% |
EN |
9.43% |
|
Andrea Alonso |
105 |
49 |
9.52% |
20.95% |
ES |
6.67% |
|
Antonio Camacho |
109 |
39 |
24.77% |
46.79% |
EN |
29.36% |
|
Brian Fuentes |
100 |
12 |
7.0% |
3.0% |
EN |
2.0% |
|
Chris Andersen |
100 |
6 |
5.0% |
2.0% |
EN |
26.0% |
|
Cicely Saunders |
110 |
2 |
7.27% |
10.91% |
EN |
1.82% |
|
Claudio Reyna |
107 |
5 |
7.48% |
2.8% |
EN |
4.67% |
|
David Cutler |
98 |
37 |
15.31% |
19.39% |
EN |
0.0% |
|
Elena Ochoa |
110 |
15 |
8.18% |
4.55% |
ES |
10.0% |
|
Emily Dickinson |
107 |
1 |
3.74% |
0.93% |
EN |
0.0% |
|
Francisco Bernis |
100 |
4 |
4.0% |
29.0% |
EN |
50.0% |
|
Franco Modigliani |
109 |
2 |
2.75% |
1.83% |
EN |
38.53% |
|
Frederick Sanger |
100 |
2 |
0.0% |
5.0% |
EN |
0.0% |
|
Gaspar Zarrías |
110 |
3 |
4.55% |
0.0% |
ES |
2.73% |
|
George Bush |
108 |
4 |
2.78% |
13.89% |
EN |
25.0% |
|
Gorka Larrumbide |
109 |
3 |
4.59% |
32.11% |
ES |
9.17% |
|
Henri Michaux |
98 |
1 |
3.06% |
1.02% |
EN |
7.14% |
|
James Martin |
100 |
48 |
5.0% |
14.0% |
EN |
2.0% |
|
Javi Nieves |
106 |
3 |
4.72% |
1.89% |
ES |
3.77% |
|
JesseGarcia |
109 |
26 |
6.42% |
16.51% |
EN |
31.19% |
|
John Harrison |
109 |
50 |
15.6% |
19.27% |
EN |
11.01% |
|
John Orozco |
100 |
9 |
11.0% |
20.0% |
EN |
4.0% |
|
John Smith |
101 |
52 |
10.89% |
10.89% |
EN |
0.0% |
|
Joseph Murray |
105 |
47 |
7.62% |
20.0% |
EN |
0.95% |
|
Julián López |
109 |
28 |
4.59% |
1.83% |
ES |
6.42% |
|
Julio Iglesias |
109 |
2 |
2.75% |
0.92% |
ES |
14.68% |
|
Katia Guerreiro |
110 |
8 |
10.91% |
0.0% |
EN |
26.36% |
|
Ken Olsen |
100 |
41 |
5.0% |
6.0% |
EN |
0.0% |
|
Lauren Tamayo |
101 |
8 |
11.88% |
10.89% |
EN |
3.96% |
|
Leonor García |
100 |
53 |
9.0% |
12.0% |
ES |
3.0% |
|
Manuel Alvar |
109 |
4 |
3.67% |
34.86% |
ES |
0.92% |
|
Manuel Campo |
103 |
7 |
3.88% |
2.91% |
ES |
0.0% |
|
María Dueñas |
100 |
5 |
6.0% |
0.0% |
ES |
14.0% |
|
Mary Lasker |
103 |
3 |
1.94% |
15.53% |
EN |
0.0% |
|
MattBiondi |
106 |
12 |
10.38% |
5.66% |
EN |
9.43% |
|
Michael Bloomberg |
110 |
2 |
6.36% |
1.82% |
EN |
0.0% |
|
Michael Collins |
108 |
31 |
1.85% |
13.89% |
EN |
0.0% |
|
Michael Hammond |
100 |
79 |
20.0% |
11.0% |
EN |
1.0% |
|
Michael Portillo |
105 |
2 |
4.76% |
0.95% |
EN |
7.62% |
|
Michel Bernard |
100 |
5 |
0.0% |
95.0% |
FR |
39.0% |
|
Michelle Bachelet |
107 |
2 |
8.41% |
4.67% |
EN |
16.82% |
|
Miguel Cabrera |
108 |
3 |
5.56% |
3.7% |
EN |
0.93% |
|
Miriam González |
110 |
43 |
11.82% |
5.45% |
ES |
29.09% |
|
Olegario Martínez |
100 |
38 |
12.0% |
10.0% |
ES |
15.0% |
|
OswaldAvery |
110 |
2 |
7.27% |
3.64% |
EN |
9.09% |
|
Palmira Hernández |
105 |
37 |
8.57% |
60.95% |
ES |
20.95% |
|
Paul Erhlich |
99 |
9 |
4.04% |
7.07% |
EN |
16.16% |
|
Paul Zamecnik |
102 |
6 |
1.96% |
6.86% |
EN |
2.94% |
|
Pedro Duque |
110 |
5 |
4.55% |
12.73% |
ES |
4.55% |
|
Pierre Dumont |
99 |
39 |
10.1% |
15.15% |
EN |
41.41% |
|
Rafael Matesanz |
110 |
6 |
7.27% |
2.73% |
EN |
44.55% |
|
Randy Miller |
99 |
52 |
12.12% |
33.33% |
EN |
0.0% |
|
Raúl González |
107 |
32 |
4.67% |
1.87% |
ES |
10.28% |
|
Richard Rogers |
100 |
40 |
13.0% |
16.0% |
EN |
9.0% |
|
Richard Vaughan |
108 |
5 |
4.63% |
5.56% |
ES |
7.41% |
|
Rita Levi |
104 |
2 |
1.92% |
1.92% |
ES |
47.12% |
|
Robin López |
102 |
10 |
12.75% |
13.73% |
EN |
1.96% |
|
Roger Becker |
103 |
29 |
4.85% |
18.45% |
EN |
13.59% |
|
Virginia Díaz |
106 |
40 |
11.32% |
16.04% |
ES |
17.92% |
|
William Miller |
107 |
40 |
7.48% |
37.38% |
EN |
0.0% |
|
AVG |
104.69 |
19.95 |
7.66% |
14.88% |
- |
12.29% |
Where:
- #Webs: Number of search results associated with the person in question.
- #C: Number of different individuals (clusters) occurring in the search results for a given person name.
- %S: Percentage of web pages pertaining to social media.
- %NR: Percentage of unrelated web pages.
- L: Most common language for a given person, based on the annotations performed by linguists.
- OL%: percentage of web pages written in a language other than the most frequent (L).
The corpus is structured in directories. Each directory belongs to a specific search query that matches the pattern “name_lastname”, and includes the search results associated with that person name. Each search result is in turn stored in a separate directory, whose name reflects the rank of that particular result in the entire list of search results. A directory with a search result contains the following files:
- The web page linked by the search result. Note that not all search results point to HTML web pages, but there are also other document formats: pdf, doc, etc.
- A metadata.xml file with the following information:
- URL of searchresult.
- ISO 639-1 codes for languages the web page is written in. Comma-separated list of languages where several were found.
- Download date.
- Name of annotator.
An example of this file is as follows:
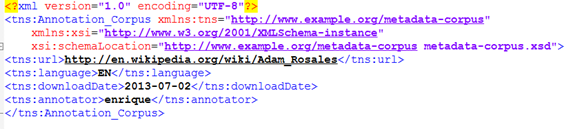
- A file with the plain text of the search results, which was extracted using Apache TiKa (https://tika.apache.org/).
There can be overlaps between clusters where a search result belongs to two or more different individuals with the same name. When a search result doesn’t belong to any individuals, then this is annotated as “Not Related”.
The corpus is available in the Downloads section.
Test Corpus
The M-WeP-NaD test corpus includes 35 different person names belonging to the MC4WePS benchmark corpus [Montalvo et al., 2016], which have been randomly sampled.
Registration
Registration for M-WePNaD task is now open and will stay open until May 8, 2017.
To register please send an email to the following address: m-wepnadorganizers@listserv.uned.es
Once registered you will receive data access details.
Submission
The submission should be a single file, formatted as follows. Each line has the following fields separated by means of tabulator spaces:
Person name Web ID Cluster ID
Where:
· The first column contains the person name to disambiguate.
· The second column contains the web page ID, that is the name of the subfolder that contains the html page and other files associated with the web page.
· The third column contains the cluster ID. The cluster IDs could be any string with no spaces.
Overlapping clusters are allowed. For example, if Adam Rosales's web page 001 is included in clusters 0 and 1, the file would contain the following lines:
…
adam rosales 001 0
…
adam rosales 001 1
…
The procedure of submission will be as follows:
- You should choose a team name that identifies your company or institution.
- The filename for each run will include the team name and a correlative submission number starting in 1. For example, TEAM_1, TEAM_2,...
- The maximum number of runs for each team is 5.
- The runs should be sent to soto.montalvo@urjc.es (Email subject: M-WePeNaD RUN SUBMISSION) in addition to the name and affiliations of the participants.
Evaluation
We will use a set of evaluation metrics that take into account overlapping clusters. The metrics are: Reliability (R), Sensibility (S) and their harmonic mean F0.5(R,S) [Amigó et al., 2013]. In this task the final value of the evaluation will be the average of F0.5(R,S) in all person names.
The Java Archive (JAR) containing the application to run the evaluation can be found in Downloads section.
The evaluator receives three parameters in the following order:
- Path where the gold standard is (pathGoldStandard).
- Path with the runs to be evaluated (pathRuns). It must be a folder that contains one or more runs. Each run is a file that follows the submission format.
- Path of the output folder.
The way to use the evaluator is the following:
java –jar Evaluator.jar pathGoldStandard pathRuns output
The output of the evaluation consists of as many files as runs plus a file called GLOBAL_RESULTS.txt which contains the average results of each run. Each run output file contains the values of R, S and F for each person name, and the mean of these values for all person names. Moreover, the R, S and F values are generated both by considering not related pages in the evaluation as well as by not considering them.
Downloads
- Training Corpus: MWePNaDTraining.zip
- Gold standard for Training Corpus: GoldStandardTraining.txt
- JAVA application to run the evaluation: Evaluator.jar
- Test Corpus: MWePNaDTest.zip
Baseline Results
- ALL IN ONE returns one cluster containing all the search results.
| System | BP(Related) | BR(Related) | F0.5(Related) | BP(ALL) | BR(ALL) | F0.5(ALL) |
| ALL_IN_ONE(Training) | 0.54 | 1.0 | 0.62 | 0.51 | 1.0 | 0.61 |
| ONE_IN_ONE(Training) | 1.0 | 0.25 | 0.34 | 1.0 | 0.2 | 0.29 |
Final Results
We provide the ranking of the results after evaluating all submissions received.
First table shows the results by not considering not related pages in the evaluation, and second table shows the results by considering them.
Results considering only related web pages:
|
System |
R |
S |
F0.5 |
|
ATMC_UNED - run 3 |
0.80 |
0.84 |
0.81 |
|
ATMC_UNED - run 4 |
0.79 |
0.85 |
0.81 |
|
ATMC_UNED - run 2 |
0.82 |
0.79 |
0.80 |
|
ATMC_UNED - run 1 |
0.79 |
0.83 |
0.79 |
|
LSI_UNED - run 3 |
0.59 |
0.85 |
0.61 |
|
LSI_UNED - run 4 |
0.74 |
0.71 |
0.61 |
|
LSI_UNED - run 2 |
0.52 |
0.93 |
0.58 |
|
LSI_UNED - run 5 |
0.52 |
0.92 |
0.57 |
|
PanMorCresp_Team - run 4 |
0.53 |
0.87 |
0.57 |
|
LSI_UNED - run 1 |
0.49 |
0.97 |
0.56 |
|
Baseline - ALL-IN-ONE |
0.47 |
0.99 |
0.54 |
|
Loz_Team - run 3 |
0.57 |
0.71 |
0.52 |
|
Loz_Team - run 5 |
0.51 |
0.83 |
0.52 |
|
Loz_Team - run 2 |
0.55 |
0.65 |
0.50 |
|
Loz_Team - run 4 |
0.50 |
0.81 |
0.50 |
|
PanMorCresp_Team - run 3 |
0.53 |
0.82 |
0.47 |
|
Loz_Team - run 1 |
0.50 |
0.76 |
0.46 |
|
PanMorCresp_Team - run 1 |
0.80 |
0.51 |
0.43 |
|
Baseline - ONE-IN-ONE |
1.0 |
0.32 |
0.42 |
|
PanMorCresp_Team - run 2 |
0.50 |
0.65 |
0.41 |
Results considering all web pages:
|
System |
R |
S |
F0.5 |
|
ATMC_UNED - run 3 |
0.79 |
0.74 |
0.75 |
|
ATMC_UNED - run 4 |
0.78 |
0.75 |
0.75 |
|
ATMC_UNED - run 1 |
0.78 |
0.73 |
0.74 |
|
ATMC_UNED - run 2 |
0.82 |
0.69 |
0.73 |
|
LSI_UNED - run 3 |
0.59 |
0.81 |
0.60 |
|
LSI_UNED - run 2 |
0.52 |
0.92 |
0.59 |
|
LSI_UNED - run 5 |
0.52 |
0.90 |
0.59 |
|
LSI_UNED - run 1 |
0.49 |
0.97 |
0.58 |
|
LSI_UNED - run 4 |
0.74 |
0.66 |
0.58 |
|
Loz_Team - run 1 |
0.49 |
0.73 |
0.58 |
|
PanMorCresp_Team - run 4 |
0.52 |
0.86 |
0.58 |
|
Baseline - ALL-IN-ONE |
0.47 |
1.0 |
0.56 |
|
Loz_Team - run 5 |
0.50 |
0.80 |
0.54 |
|
Loz_Team - run 3 |
0.56 |
0.66 |
0.53 |
|
Loz_Team - run 4 |
0.49 |
0.78 |
0.52 |
|
Loz_Team - run 2 |
0.54 |
0.61 |
0.50 |
|
PanMorCresp_Team - run 3 |
0.53 |
0.81 |
0.50 |
|
PanMorCresp_Team - run 2 |
0.49 |
0.62 |
0.43 |
|
PanMorCresp_Team - run 1 |
0.79 |
0.46 |
0.40 |
|
Baseline - ONE-IN-ONE |
1.0 |
0.25 |
0.36 |
The M-WePNaD Organizing Committee appreciates the interest on this task of all the participants.
References