Why EXIST?
Welcome to the website of EXIST 2024, the fourth edition of the sEXism Identification in Social neTworks task at CLEF 2024.
EXIST is a series of scientific events and shared tasks on sexism identification in social networks. EXIST aims to capture sexism in a broad sense, from explicit misogyny to other subtle expressions that involve implicit sexist behaviours (EXIST 2021, EXIST 2022, EXIST 2023). The fourth edition of the EXIST shared task will be held as a Lab in CLEF 2024, on September 9-12, 2024, in the University of Grenoble Alpes, Grenoble, France.
Social Networks are the main platforms for social complaint, activism, etc. Movements like #MeTwoo, #8M or #Time’sUp have spread rapidly. Under the umbrella of social networks, many women all around the world have reported abuses, discriminations and other sexist experiences suffered in real life. Social networks are also contributing to the transmission of sexism and other disrespectful and hateful behaviours. In this context, automatic tools not only may help to detect and alert against sexism behaviours and discourses, but also to estimate how often sexist and abusive situations are found in social media platforms, what forms of sexism are more frequent and how sexism is expressed in these media. This Lab will contribute to developing applications to detect sexism.
While the three previous editions focused solely on detecting and classifying sexist textual messages, this new edition incorporates new tasks that center around images, particularly memes. Memes are images, typically humorous in nature, that are spread rapidly by social networks and Internet users. With this addition, we aim to encompass a broader spectrum of sexist manifestations in social networks, especially those disguised as humor. Consequently, it becomes imperative to develop automated multimodal tools capable of detecting sexism in both text and memes.
Similar to the approach in the 2023 edition, this edition will also embrace the Learning With Disagreement (LeWiDi) paradigm for both the development of the dataset and the evaluation of the systems. The LeWiDi paradigm doesn’t rely on a single “correct” label for each example. Instead, the model is trained to handle and learn from conflicting or diverse annotations. This enables the system to consider various annotators’ perspectives, biases, or interpretations, resulting in a fairer learning process.
In previous editions, 75 teams from more than 20 countries submitted their results achieving impressive results, especially in the sexism detection task. However, there is still room for improvement, especially in when the problem is addressed under the LeWeDi paradigm.

|

|
|
Tasks
Participants will be asked to classify “tweets” or “memes” (in English and Spanish) according to the following five tasks:
TASK 1: Sexism Identification in Tweets
The first task is a binary classification. The systems have to decide whether or not a given tweet contains sexist expressions or behaviours (i.e., it is sexist itself, describes a sexist situation or criticizes a sexist behaviour). The following tweets show examples of sexist and not sexist messages.
- SEXIST:
- “Mujer al volante, tenga cuidado!"
- “People really try to convince women with little to no ass that they should go out and buy a body. Like bih, I don’t need a fat ass to get a man. Never have."
- NOT SEXIST:
- “Alguien me explica que zorra hace la gente en el cajero que se demora tanto."
- "@messyworldorder it’s honestly so embarrassing to watch and they’ll be like “not all white women are like that”"
TASK 2: Source Intention in Tweets
Once a message has been classified as sexist, the second task aims to categorize the message according to the intention of the author, which provides insights in the role played by social networks on the emission and dissemination of sexist messages. In this task, we propose a ternary classification task:
-
DIRECT: the intention was to write a message that is sexist by itself or incites to be sexist, as in:
- A woman needs love, to fill the fridge, if a man can give this to her in return for her services (housework, cooking, etc), I don’t see what else she needs.
- Women shouldn’t code…perhaps be influencer/creator instead…it’s their natural strength.
-
REPORTED: the intention is to report and share a sexist situation suffered by a woman or women in first or third person, as in:
- I doze in the subway, I open my eyes feeling something weird: the hand of the man sat next to me on my leg #SquealOnYourPig.
- Today, one of my year 1 class pupils could not believe he’d lost a race against a girl.
-
JUDGEMENTAL: the intention was to judge, since the tweet describes sexist situations or behaviours with the aim of condemning them.
- As usual, the woman was the one quitting her job for the family’s welfare…
- 21st century and we are still earning 25% less than men #Idonotrenounce.
TASK 3: Sexism Categorization in Tweets
Many facets of a woman’s life may be the focus of sexist attitudes including domestic and parenting roles, career opportunities, sexual image, and life expectations, to name a few. Automatically detecting which of these facets of women are being more frequently attacked in social networks will facilitate the development of policies to fight against sexism. According to this, each sexist tweet must be categorized in one or more of the following categories
-
IDEOLOGICAL AND INEQUALITY: The text discredits the feminist movement, rejects inequality between men and women, or presents men as victims of gender-based oppression.
- “Mi hermana y mi madre se burlan de mí por defender todo el tiempo los derechos de todos y me acaban de decir feminazi, la completaron”.
- “I think the whole equality thing is getting out of hand. We are different, thats how were made!”.
-
STEREOTYPING AND DOMINANCE: The text expresses false ideas about women that suggest they are more suitable to fulfill certain roles (mother, wife, family caregiver, faithful, tender, loving, submissive, etc.), or inappropriate for certain tasks (driving, hardwork, etc), or claims that men are somehow superior to women.
- “@Paula2R @faber_acuria A las mujeres hay que amarlas…solo eso… Nunca las entenderás.”.
- “Most women no longer have the desire or the knowledge to develop a high quality character, even if they wanted to.”.
-
OBJECTIFICATION: The text presents women as objects apart from their dignity and personal aspects, or assumes or describes certain physical qualities that women must have in order to fulfill traditional gender roles (compliance with beauty standards, hypersexualization of female attributes, women’s bodies at the disposal of men, etc.).
- ““Pareces una puta con ese pantalón” - Mi hermano de 13 cuando me vio con un pantalón de cuero”.
- “Don’t get married than blame all woman for your poor investment. You should of got a hooker but instead you choose to go get a wedding ring.”.
-
SEXUAL VIOLENCE: Sexual suggestions, requests for sexual favors or harassment of a sexual nature (rape or sexual assault) are made.
- “#MeToo Estas 4 no han conseguido su objetivo.El juez estima que se abrieron de patas https://t.co/GSHiiwqY6Aánta lagartona hay en este \metoo"!👇🏻👇🏻🤔🤔🤔 https://t.co/8t5VmFIUFn"”
- “fuck that cunt, I would with my fist”.
-
MISOGYNY AND NON-SEXUAL VIOLENCE: The text expressses hatred and violence towards women.
- “Las mujeres de hoy en dia te enseñar a querer… estar soltero”
- “Some woman are so toxic they don’t even know they are draining everyone around them in poison. If you lack self awareness you won’t even notice how toxic you really are”.
Task 4: Sexism Identification in Memes
This is a binary classification task consisting on deciding whether or not a given meme is sexist. The following figures are some examples of sexist and not sexist memes, respectively.


Task 5: Source Intention in Memes
As in task 2, this task aims to categorize the meme according to the intention of the author, which provides insights in the role played by social networks on the emission and dissemination of sexist messages. Due to the characteristics of the memes, the REPORTED label is virtually null, so in this task systems should only classify memes with DIRECT or JUDGEMENTAL labels. The following figures are some examples of them, respectively.


Task 6: Sexism Categorization in Memes
This task aims to classify sexist memes according to the categorization provided for Task 3: (i) IDEOLOGICAL AND INEQUALITY, (ii) STEREOTYPING AND DOMINANCE, (iii) OBJECTIFICATION, (iv) SEXUAL VIOLENCE and (v) MISOGYNY AND NON-SEXUAL VIOLENCE. The following figures are some examples of categorized memes.

(a) Stereotyping

(e) Ideological

(c) Objectification

(d) Misogyny
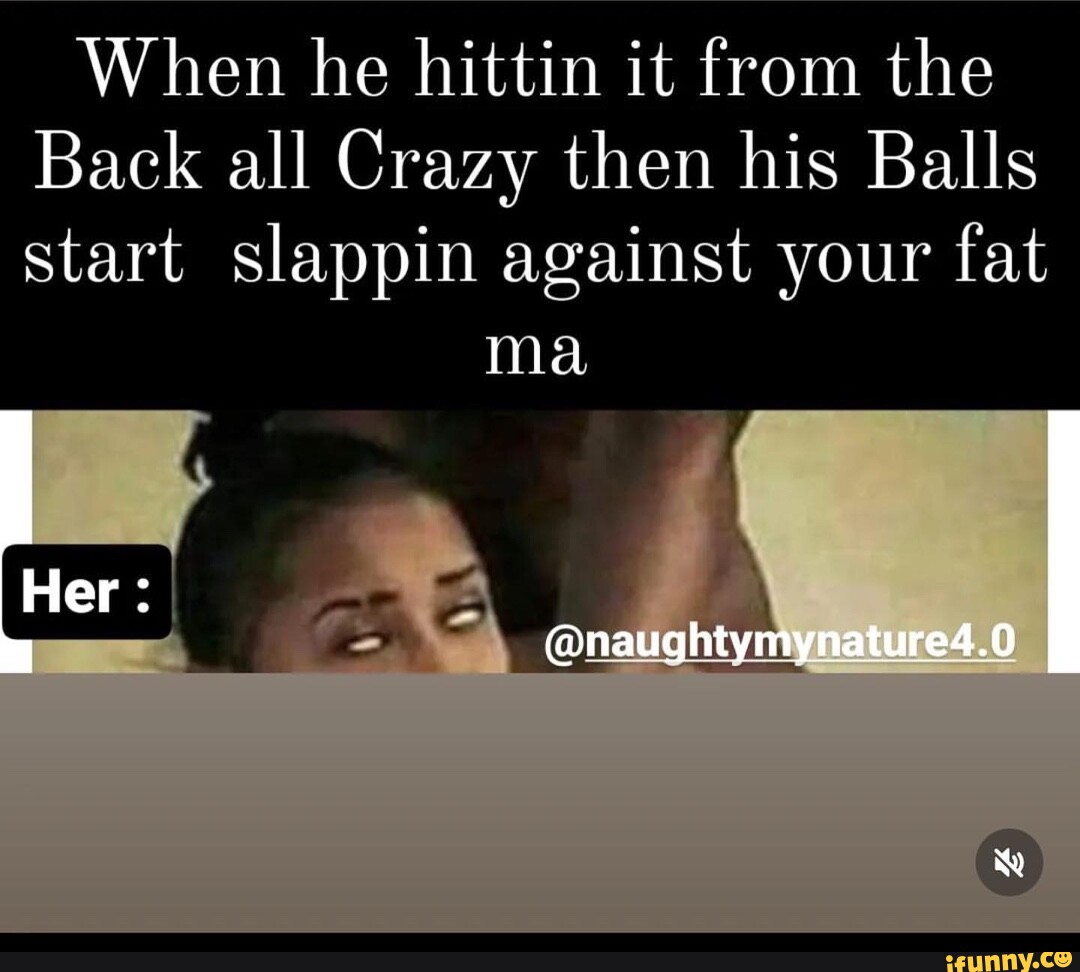
(b) Sexual violence
How to participate
If you want to participate in the EXIST 2024 shared task at CLEF 2024, please proceed to register for the lab at CLEF 2024 Labs Registration site. You will receive information about how to join our Google Group, where EXIST-Datasets, EXIST-Communications, EXIST-Questions/Answers, and EXIST-Guidelines will be provided to the participants.
Participants will be required to submit their runs and will have the possibility to provide a technical report that should include a brief description of their approach, focusing on the adopted algorithms, models and resources, a summary of their experiments, and an analysis of the obtained results. Although we recommend to participate in all tasks, participants are allowed to participate just in one of them (e.g. Task 1).
Publications
Technical reports will be published in CLEF 2024 Proceedings at CEUR-WS.org.
Important dates
- 13 November 2023 Registration open.
- 4 March 2024 Training and development sets available.
- 15 April 2024 Test set available.
- 22 April 2024 Registration closes.
6 May 2024 Runs submission due to organizers.Extended Deadline: 10 May 2024 Runs submission due to organizers.- 20 May 2024 Results notification to participants.
- 3 June 2024 Submission of Working Notes by participants.
19 June 2024 Notification of acceptance (peer-reviews).Extended Deadline: 24 June 2024 Notification of acceptance (peer-reviews).3 July 2024 Camera-ready participant papers due to organizers.Extended Deadline: 6 July 2024 Camera-ready participant papers due to organizers.- 9-12 September 2024 EXIST 2024 at CLEF Conference.
Note: All deadlines are 11:59PM UTC-12:00 (“anywhere on Earth”).
Dataset
Since 2021, the primary objective of EXIST campaigns has been the identification of sexism in tweets. Three corpora of annotated tweets have been collected for different EXIST tasks.
Likewise, the focus of EXIST 2024 is to detect sexism in text, using the EXIST 2023 dataset, but we also extent the focus to memes. Memes are images, usually with text captions, that typically carry humor and spread through social media, forums, or other digital platforms. They can be used to spread false information, perpetuate stereotypes or humiliate people.
In EXIST 2024, we have curated a lexicon of terms and expressions leading to sexist memes, derived from expressions proven representative in identifying sexism in previous EXIST editions. The set of seeds encompasses diverse topics, incorporating terms with varying degrees of use in both sexist and non-sexist contexts, all centered around women. The final set contains 250 terms, with 112 in English and 138 in Spanish.
Crawling
The terms were used as search queries on Google Images to obtain the top 100 images. Rigorous manual cleaning procedures were applied, defining memes, and ensuring removal of noise like textless images, text-only images, ads, and duplicates from the dataset. The final set of memes consists of more than 3,000 memes per language.
Since the proportion of memes per term is very heterogeneous, we have discarded the most unbalanced seeds and made sure that all seeds have at least five memes. Furthermore, the final data set has been the result of obtaining the most equitable distribution of memes per seed. To avoid introducing selection bias, we randomly selected memes, adhering to the appropriate distribution per seed. As a result, we have more than 2,000 memes per language for the training set and more than 500 memes per language for the test set.
Labeling process
As in the previous edition, we have considered some sources of “label bias”. Label bias may be introduced by the socio-demographic differences of the persons that participate in the annotation process, but also when more than one possible correct label exists or when the decision on the label is highly subjective. In order to mitigate label bias, we consider two different social and demographic parameters: gender (MALE/FEMALE) and age (18-22 y.o./23-45 y.o./+46 y.o). Each meme was annotated by 6 crowdsourcing annotators selected through the the Prolific app, following the guidelines developed by two experts in gender issues.
As new feature in the datasets, both 2023 and 2024, we will include three additional demographic characteristic of each anotator: level of education, ethnicity and country of residence.
Learning with disagreements
The assumption that natural language expressions have a single and clearly identifiable interpretation in a given context is a convenient idealization, but far from reality, especially in highly subjective task as sexism identification. The learning with disagreements paradigm aims to deal with this by letting systems learn from datasets where no gold annotations are provided but information about the annotations from all annotators, in an attempt to gather the diversity of views. Following methods proposed for training directly from the data with disagreements, instead of using an aggregated label, we will provide all annotations per instance for the 6 different strata of annotators.
More details about the dataset are provided in the task overview (bias consideration, annotation process, quality experiments, inter-annotator agreement, etc.).
Download ALL EXIST Datasets
If you want to access EXIST Datasets for research purpose, please fill this form.
Evaluation
From the point of view of evaluation metrics, our six tasks can be described as:
- Tasks 1 and 4 (sexism identification): binary classification, mono label.
- Tasks 2 and 5 (source intention): multiclass hierarchical classification, mono label. The hierarchy of classes has a first level with sexist/not sexist, and a second level for the sexist category with three/two mutually exclusive subcategories: direct, reported and judgemental. A suitable evaluation metric must reflect the fact that a confusion between not sexist and a sexist category is more severe than a confusion between two sexist subcategories.
- Tasks 3 and 6 (sexism categorization): multiclass hierarchical classification, multi label. Again, the first level is a binary distinction between sexist/not sexist, and there is a second level for the sexist category that includes ideological & inequality, stereotyping and dominance, objectification, sexual violence, misogyny and non-sexual violence. These classes are not mutually exclusive: a tweet/meme may belong to several subcategories at the same time.
The learning with disagreements paradigm can be considered in both sides of the evaluation process:
- The ground truth. In a “hard” setting, variability in the human annotations is reduced to a gold standard set of categories, hard labels, that are assigned to each item (e.g., using majority vote). In a “soft” setting, the gold standard is the full set of human annotations with their variability. Therefore, the evaluation metric incorporates the proportion of human annotators that have selected each category, soft labels. Note that in tasks 1, 2, 4 and 5, which are mono label problems, the sum of the probabilities of each class must be one. But in tasks 3 and 6, which are multi label, each annotator may select more than one category for a single item. Therefore, the sum of the probabilities of each class may be larger than one.
- The system output. In a “hard”, traditional setting, the system predicts one or more categories for each item. In a “soft” setting, the system predicts a probability for each category, for each item. The evaluation score is maximized when the probabilities predicted match the actual probabilities in a soft ground truth. Again, note that in tasks 3 and 6, which is a multi-label problem, the probabilities predicted by the system for each of the categories do not necessarily add up to one.
For each of the tasks, two types of evaluation will be reported:
- Hard-hard: hard system output and hard ground truth.
- Soft-soft: soft system output and soft ground truth.
For all tasks and all types of evaluation (hard-hard and soft-soft) we will use the same official metric: ICM (Information Contrast Measure) (Amigó and Delgado, 2022). ICM is a similarity function that generalizes Pointwise Mutual Information (PMI), and can be used to evaluate system outputs in classification problems by computing their similarity to the ground truth categories. As there is not, to the best of our knowledge, any current metric that fits hierarchical multi-label classification problems in a learning with disagreement scenario, we have defined an extension of ICM (ICM-soft) that accepts both soft system outputs and soft ground truth assignments.
For each of the tasks, the evaluation will be performed in the two modes described above, as follows:
- Hard-hard evaluation. For systems that provide a hard, conventional output, we will provide a hard-hard evaluation. To derive the hard labels in the ground truth from the different annotators’ labels, we use a probabilistic threshold computed for each task. As a result, for tasks 1 and 4, the class annotated by more than 3 annotators is selected; for tasks 2 and 5, the class annotated by more than 2 annotators is selected; and for tasks 3 and 6 (multi-label), the class annotated by more than 1 annotator are selected. Items for which there is no majority class (i.e., no class receives more probability than the threshold) will be removed from this evaluation scheme. The official metric will be the original ICM (as defined in (Amigó and Delgado, 2022)). We will also report and compare systems with F1 (the harmonic average of precision and recall). In tasks 1 and 4, we will use F1 for the positive class. In the remaining tasks, we will use the average of F1 for all classes. Note, however, that F1 is not ideal in our experimental setting: although it can handle multi-label situations, it does not consider the relationships between classes: a mistake between not sexist and any of the sexist subclasses, and a mistake between two of the positive subclasses, are penalized equally, although the former is a more severe error.
- Soft-soft evaluation. For systems that provide probabilities for each category, we will provide a soft-soft evaluation that compares the probabilities assigned by the system with the probabilities assigned by the set of human annotators. As in the previous case, we will use ICM-soft as the official evaluation metric in this variant. We may also report additional metrics in the final report.
Enrique Amigó and Agustín Delgado. 2022. Evaluating Extreme Hierarchical Multi-label Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5809–5819, Dublin, Ireland. Association for Computational Linguistics.
Results
Below are the official leaderboards for all participants and tasks in all evaluations contexts:
Details:
- Hard-hard: hard system output and hard ground truth.
- Metrics:
- ICM-Hard: ICM is the official metric for the ranking (as defined in Amigó and Delgado, 2022).
- ICM-Hard Norm: ICM hard normalized.
- F1: in Task 1, we provide results for F1 for the positive class, “YES”. In Tasks 2 and 3, we provide results for the average of F1 for all classes.
- Baselines:
- Majority class: non-informative baseline that classifies all instances as the majority class.
- Minority class: non-informative baseline that classifies all instances as the minority class.
- Metrics:
- Soft-soft: soft system output and soft ground truth.
- Metrics:
- ICM-Soft: ICM soft is the official metric for the ranking (as adapted from Amigó and Delgado, 2022).
- ICM-Soft Norm: ICM soft normalized.
- Cross Entropy: in task 1 and task 2 we provide results for cross entropy measure.
- Baselines:
- Majority class: non-informative baseline that classifies all instances as the majority class. Note that the probability of the class has been set to 1.
- Minority class: non-informative baseline that classifies all instances as the minority class. Note that the probability of the class has been set to 1.
- Metrics:
Enrique Amigó and Agustín Delgado. 2022. Evaluating Extreme Hierarchical Multi-label Classification. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5809–5819, Dublin, Ireland. Association for Computational Linguistics.
EXIST 2024 Lab Program
EXIST 2024 is co-located with the CLEF Conference and will be held face-to-face on Wednesday September 11th 2024 and Thursday September 12th 2024.
Wednesday, September 11th
-
11:15 – 12:45 Overview of EXIST 2024 – Learning with Disagreement for Sexism Identification and Characterization in Social Networks and Memes. Laura Plaza, Jorge Carrillo-de-Albornoz, Víctor Ruiz, Alba Maeso, Berta Chulvi, Paolo Rosso, Enrique Amigó, Julio Gonzalo, Roser Morante, Damiano Spina
-
15:30 – 16:30 Poster Session
Thursday, September 12th
-
11:15 - 12:50 EXIST 2024 Parallel Session: Sexism Detection and Categorization in Memes
- 11:15 – 11:20: Welcome and Opening Remarks.
- 11:20 – 12:10: Keynote Talk: “Keeping Social Media Safe and Factual in the Era of Large Language Models”. Preslav Nakov
- 12:10 - 12:30: A Contrastive Learning Based Approach to Detect Sexism in Memes. Fariha Maqbool, Elisabetta Fersini
- 12:30 - 12:50: PINK at EXIST2024: A Cross-Lingual and Multi-Modal Transformer Approach for Sexism Detection in Memes. Giulia Rizzi, David Gimeno-Gómez, Elisabetta Fersini, Carlos-D. Martínez-Hinarejos
-
12:50 - 14:00 LUNCH
-
14:00 – 15:30 EXIST 2024 Parallel Session: Sexism Detection and Categorization in Tweets
- 14:00 - 14:20: Multilingual Sexism Identification via Fusion of Large Language Models. Sahrish Khan, Gabriele Pergola, Arshad Jhumka
- 14:20 - 14:40: Stacked Reflective Reasoning in Large Neural Language Models. Kapioma Villarreal-Haro, Fernando Sánchez-Vega, Alejandro Rosales-Pérez, Adrián Pastor López-Monroy
- 14:40 - 15:00: Sexism Identification in Tweets using BERT and XLM – Roberta. Rania Siddiqui, Faryal Khan, Samin Rizwan, Maha Usmani, Faisal Alvi, Abdul Samad
- 15:00 - 15:20: Better Together: LLM and Neural Classification Transformers to Detect Sexism. Judith Tavarez-Rodríguez, Fernando Sánchez-Vega, Alejandro Rosales-Pérez, Adrián Pastor López-Monroy
- 15:20 - 15:30: Final Discussion and Suggestions.
EXIST 2024 Proceedings
Overview Paper:
- Laura Plaza, Jorge Carrillo-de-Albornoz, Victor Ruiz, Alba Maeso, Berta Chulvi, Paolo Rosso, Enrique Amigó, Julio Gonzalo, Roser Morante and Damiano Spina. (2024). Overview of EXIST 2024 - Learning with Disagreement for Sexism Identification and Characterization in Tweets and Memes. In L. Goeuriot et al. (Eds.), Experimental IR Meets Multilinguality, Multimodality, and Interaction (pp. 93–117). Cham: Springer Nature Switzerland.
Extended Overview Paper:
- Laura Plaza, Jorge Carrillo de Albornoz, Víctor Ruiz, Alba Maeso, Berta Chulvi, Paolo Rosso, Enrique Amigó, Julio Gonzalo, Roser Morante, Damiano Spina: Overview of EXIST 2024 - Learning with Disagreement for Sexism Identification and Characterization in Tweets and Memes (Extended Overview). Working Notes of the Conference and Labs of the Evaluation Forum (CLEF 2024). CEUR Working Notes Vol-3740.: 908-941
Working Notes:
- All proceedings available at: EXIST 2024 Proceedings.
Organizers
Alba Maeso Olmos
Universitat Politècnica de València
Researcher in Computational Linguistic
Berta Chulvi
Universitat Politècnica de València
Researcher in Computational Social Science
Damiano Spina
RMIT University
Senior Lecturer
Enrique Amigó
UNED
Associate Professor
Jorge Carrillo-de-Albornoz
UNED
RMIT University
Associate Professor
Julio Gonzalo
UNED
Full Professor
Laura Plaza
UNED
RMIT University
Associate Professor
Paolo Rosso
Universitat Politècnica de València
Full Professor
Roser Morante
UNED
Researcher in Computational Linguistic
Víctor Ruiz García
UNED
Researcher in Computational Linguistic
Sponsors
ARC Centre of Excellence for Automated Decision-Making and Society (ADM+S) (CE200100005)
RMIT University
FairTransNLP Project
(PID2021-124361OB-C31 and PID2021-124361OB-C32)
Spanish Ministry of Science and Innovation (funded by MCIN/AEI/10.13039/501100011033 and by ERDF, EU A way of making Europe)
Pattern Recognition and Human Language Technologies (PRHLT) Research Center
Universitat Politècnica de València
Space for Observation of AI in Spanish
UNED and RED.ES, M.P., ref. C039/21- OT
Spanish Ministry of Economy and Competitiveness
Contact
If you have any specific question about the EXIST 2024, we may ask you to let us know through the Google Group EXIST 2024 at CLEF 2024.
For any other question that does not directly concern the shared task, please write to Jorge Carrillo-de-Albornoz.